Vite P2P Network
-
Introduction
P2P is generally called peer-to-peer network. In comparison to the traditional C/S architecture, P2P has following features:
- Decentralization. Dispatched center and database does not exist in P2P network.
- Each of the nodes contains the same logic and state<sup>1</sup>, There is no concept of client or server.
- Unreliability. The connections between nodes are unreliable.
C/S Architecture

P2P Architecture

P2P architecture is naturally suitable for decentralized blockchain network.
[1] Note that this only happens at the network layer. In upper layers such as the application layer, nodes will have different roles between full nodes and lightweight nodes.
Structured Model and DHT
Since P2P networks are decentralized and do not have a central database, nodes can join and leave at any time. As such, resource allocation becomes a major issue. The strategy to locate resources quickly and effectively is known as content routing.
In search of a solution, the P2P network model has evolved through several different forms, including centralized, pure distributed, hybrid, and structured<sup>2</sup>.
- Centralized model uses master index, distributed storage and strong-dependency index server. This model is not reliable enough.
- In pure distributed model, nodes and resources are randomly distributed and disordered, therefore could suffer from message flooding and storms in ease.
- Hybrid network contains a combination of super nodes and ordinary nodes, where super nodes are more likely to dominate the network.
The structured P2P network is generally based on a distributed hash table (DHT), which hashes the resource to obtain the resource ObjectID and allocates NodeID to every node in the network. Ideally, ObjectID is correspondent to NodeID and resource i is stored in node i 3. In this way, node n can directly request node i for resource i.
Sorting NodeIDs by certain rules is a helpful for performance enhancement. In this scenario, if node n does not have the information of node i, it will first request from the neighbors of node i to reduce route hops and improve efficiency.
In structured model, mapped nodes and resources are recorded in DHT. The network load is more balanced with better scalability.
[2] Network Model Reference: https://en.wikipedia.org/wiki/Peer-to-peer
[3] In actual implementation, resources are stored in mapped nodes and their neighbors to improve redundancy
KAD
DHT has many algorithm implementations, such as Chord<sup>3</sup> Pastry<sup>4</sup> CAN<sup>5</sup> and KAD<sup>6</sup>, etc.
Vite adopts KAD, the most popular DHT algorithm nowadays. Configurable ED25519 public key is used as NodeID.
[3] Chord Reference: https://en.wikipedia.org/wiki/Chord_(peer-to-peer)
[4] Pastry Reference: http://www.freepastry.org/PAST/overview.pdf
[5] CAN paper: http://www.icir.org/sylvia/thesis.ps
[6] Kademlia paper: https://pdos.csail.mit.edu/~petar/papers/maymounkov-kademlia-lncs.pdf
The following are the primary ideas of KAD algorithm:
- Using XOR to calculate the logical distance between two NodeIDs.
- Each node saves N K-buckets, where N is the bit number of the NodeID and K can be adjusted on demand. The distance between current node and nodes in the i-th K-bucket lies between 2<sup>i</sup> and 2<sup>i+1</sup>.
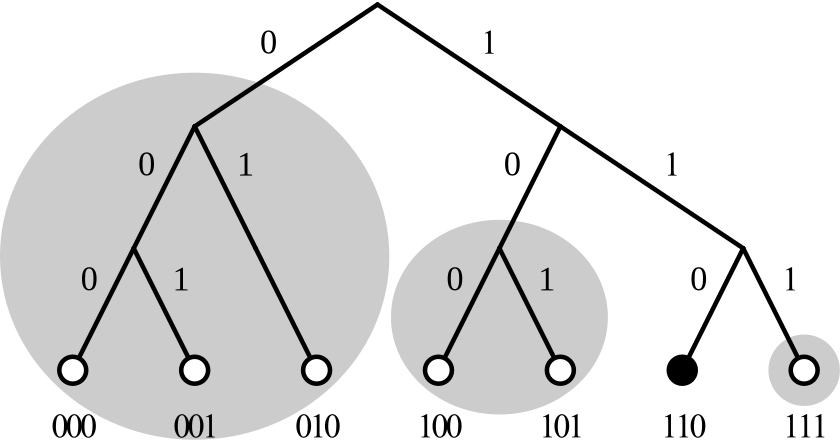
All nodes are assigned to N subtrees, and K nodes are selected from each subtree and stored in the corresponding K-bucket.
When node A requests resource i, given A XOR i is equal to d, node A may search from the log<sub>2</sub>d K-bucket and request resource i directly if node i is found.
Otherwise, a parallel query should be performed within the K nodes. In this process, these nodes return the K nodes who are nearest to node i in distance in their K-buckets to node A, thereby locking the position of node i gradually.
Algorithm complexity of KAD is O(log n)
KAD summary
KAD has the following advantages over other algorithms such as Chord:
- Easy to implement
- Flexible enough (N, K and parallel requests can be altered)
- Excellent fault tolerance and scalability
Necessary adjustment is acceptable in real application implementation. For example, Vite NodeID has 256-bit length, but the K-bucket number is less than 256.
Node communication
There are 4 types of messages:
- PING To test a node is online or not
- STORE Require nodes to store data
- FIND_NODE find a node
- FIND_VALUE find a resource. similar to FIND_NODE
Currently there is no requirement for STORE message (the block synchronization logic has been implemented in Vite Wire Protocol layer, not in p2p layer). PING and FIND_NODE are most used in Vite.
Node discovery
When a new Vite node initiates, it queries pre-configured bootnodes for its location first and then repeats this query on the nodes returned by bootnodes, until no closer nodes are returned. By then, the K-buckets of this node has been built successfully.
Node maintenance
Because nodes may change frequently, KAD uses the following strategies to maintain K-buckets.
- The nodes in each bucket are arranged in reverse order by the most recent communication timestamp. The most recent contacted node is attached at bucket tail.
- Once there is an incoming communication request, the algorithm goes to check if the request node is already in bucket in following steps,
- If it exists, move it to the tail of the bucket.
- If it doesn’t exist and the bucket is not full, put it at the head of the bucket.
- If it doesn’t exist and the bucket is full, try to PING the head node(the longest un-communicated in bucket) and discard the new node if success, otherwise, replace the head node with new node.
This strategy guarantees that nodes are updated in time. The more active the nodes are, the less likely for them to be replaced. In the meantime, the network is more stable.
Summary
Vite has chosen a proven P2P network solution, where Vite communication protocols such as transactions, block broadcasting and node synchronization are built.